Планировщик операционной системы
Краткий пересказ перевода:
- Многопоточность в программировании требует учета различных факторов, таких как переключение контекста и планирование работы.
- Переключение контекста может снизить производительность, особенно при работе с привязкой к процессору.
- Ограничение минимального временного интервала помогает сбалансировать количество потоков и производительность.
- Пулы потоков могут быть полезны для управления количеством потоков и достижения наилучшей пропускной способности приложения.
- Системы кэширования играют важную роль в производительности многопоточных приложений, и необходимо учитывать их механику.
- При написании многопоточных приложений необходимо учитывать системы кэширования и принимать решения о планировании.
Введение
Дизайн и поведение планировщика Go позволяет вашим многопоточным программам Go быть более эффективными. Это происходит благодаря механическим симпатиям планировщика Go к планировщику операционной системы (OS). Однако, если дизайн и поведение вашего многопоточного программного обеспечения Go механически не соответствуют тому, как работают планировщики, ничто из этого не будет иметь значения. Важно иметь общее представление о том, как работают планировщики операционной системы и Go, чтобы правильно спроектировать ваше многопоточное программное обеспечение.
Эта статья, состоящая из нескольких частей, будет посвящена высокоуровневой механике и семантике планировщиков. Я предоставлю достаточно подробностей, чтобы вы могли наглядно представить, как все работает, и принимать более эффективные инженерные решения. Несмотря на то, что многое зависит от инженерных решений, которые вам необходимо принять для многопоточных приложений, механика и семантика составляют важнейшую часть необходимых вам базовых знаний.
Планировщик операционной системы
Планировщики операционной системы - это сложные программные продукты. Они должны учитывать компоновку и настройку оборудования, на котором они работают. Это включает, но не ограничивается наличием нескольких процессоров и ядер, кэшей процессора и NUMA. Без этих знаний планировщик не может быть максимально эффективным. Замечательно то, что вы все еще можете разработать хорошую мысленную модель того, как работает планировщик операционной системы, не углубляясь в эти темы.
Ваша программа - это просто серия машинных инструкций, которые необходимо выполнять последовательно одну за другой. Чтобы это произошло, операционная система использует концепцию потока. Задача Потока состоит в том, чтобы учитывать и последовательно выполнять набор назначенных ему инструкций. Выполнение продолжается до тех пор, пока у потока больше не останется инструкций для выполнения. Вот почему я называю поток “путем выполнения”.
Каждая запускаемая вами программа создает процесс, и каждому процессу присваивается начальный поток. Потоки имеют возможность создавать новые потоки. Все эти разные потоки выполняются независимо друг от друга, и решения о планировании принимаются на уровне потока, а не на уровне процесса. Потоки могут выполняться одновременно (каждый по очереди на отдельном ядре) или параллельно (каждый выполняется одновременно на разных ядрах). Потоки также поддерживают свое собственное состояние, чтобы обеспечить безопасное, локальное и независимое выполнение своих инструкций.
Планировщик операционной системы отвечает за то, чтобы ядра не простаивали, если есть потоки, которые могут выполняться. Он также должен создавать иллюзию, что все потоки, которые могут выполняться, выполняются одновременно. В процессе создания этой иллюзии планировщику необходимо запускать потоки с более высоким приоритетом по сравнению с потоками с более низким приоритетом. Однако потоки с более низким приоритетом нельзя ограничивать во времени выполнения. Планировщику также необходимо максимально минимизировать задержки при планировании, принимая быстрые и разумные решения.
Для этого многое зависит от алгоритмов, но, к счастью, отрасль может использовать десятилетия работы и опыта. Чтобы лучше понять все это, полезно описать и определить несколько важных концепций.
Выполнение инструкций
Счетчик программ (PC), который иногда называют указателем команд (IP), - это то, что позволяет потоку отслеживать следующую команду для выполнения. В большинстве процессоров ПК указывает на следующую инструкцию, а не на текущую.

Если вы когда-либо видели трассировку стека в программе Go, вы могли заметить эти маленькие шестнадцатеричные числа в конце каждой строки. Ищите +0x39 и +0x72 в листинге 1.
Листинг 1
1 | goroutine 1 [running]: |
Эти числа представляют смещение значения PC от вершины соответствующей функции. Значение +0x39 смещения PC представляет следующую инструкцию, которую поток выполнил бы внутри example функции, если бы программа не запаниковала. Значение 0+x72 смещения ПК - это следующая команда внутри main функции, если управление возвращалось к этой функции. Что более важно, команда, предшествующая этому указателю, сообщает вам, какая команда выполнялась.
Посмотрите на программу ниже в листинге 2, которая вызвала трассировку стека из листинга 1
Листинг 2
1 | https://github.com/ardanlabs/gotraining/blob/master/topics/go/profiling/stack_trace/example1/example1.go |
Шестнадцатеричное число +0x39 представляет смещение ПК для инструкции внутри example функции, которое на 57 (базовые 10) байт ниже начальной инструкции для функции. В листинге 3 ниже вы можете увидеть objdump из example функции из двоичного файла. Найдите 12-ю инструкцию, которая указана внизу. Обратите внимание на строку кода выше, которая является вызовом этой инструкции panic.
Листинг 3
1 | $ go tool objdump -S -s "main.example" ./example1 |
Помните: ПК - это следующая инструкция, а не текущая. Листинг 3 - хороший пример инструкций на базе amd64, за последовательное выполнение которых отвечает поток для этой программы Go.
Состояния потоков (Thread States)
Еще одной важной концепцией является состояние потока, которое определяет роль, которую планировщик выполняет в потоке. Поток может находиться в одном из трех состояний: Ожидающем(Waiting), Готовом к выполнению(Runnable) или Выполняющимся (Executing).
Ожидание(Waiting): это означает, что поток остановлен и ожидает чего-либо, чтобы продолжить. Это может быть по таким причинам, как ожидание аппаратного обеспечения (диск, сеть), операционной системы (системные вызовы) или вызовов синхронизации (атомарные, мьютексы). Эти типы задержек являются основной причиной низкой производительности.
Возможность выполнения (Готовность- Runnable): Это означает, что потоку требуется время на ядре, чтобы он мог выполнить назначенные ему машинные инструкции. Если у вас много потоков, которым требуется время, то потокам приходится ждать дольше, чтобы получить время. Кроме того, индивидуальный промежуток времени, который получает любой данный поток, сокращается, поскольку больше потоков конкурируют за время. Этот тип задержки планирования также может быть причиной низкой производительности.
Выполнение(Executing): Это означает, что поток помещен в ядро и выполняет свои машинные инструкции. Работа, связанная с приложением, выполняется. Это то, чего хотят все.
Типы работ (Types Of Work)
Поток(Thread) может выполнять два типа работы. Первый называется привязанным к процессору(CPU-Bound), а второй - привязанным к вводу-выводу(IO-Bound).
Привязка к процессору(CPU-Bound): Это работа, которая никогда не создает ситуации, при которой поток может быть переведен в состояние ожидания. Это работа, при которой постоянно выполняются вычисления. Поток, вычисляющий число Пи(Pi=3.14…..N) до N-й цифры, будет привязан к процессору.
Привязка к вводу-выводу(IO-Bound): Это работа, которая переводит потоки в состояния ожидания(Waiting). Это работа, которая заключается в запросе доступа к ресурсу по сети или выполнении системных вызовов в операционной системе. Поток, которому требуется доступ к базе данных, будет привязан к вводу-выводу(IO-Bound). Я бы включил события синхронизации (мьютексы mutexes, атомарные atomic), которые заставляют поток ожидать, как часть этой категории.
Переключение контекста (Context Switching)
Если вы работаете в Linux, Mac или Windows, вы работаете в операционной системе с упреждающим планировщиком. Это означает несколько важных вещей.
Во-первых, это означает, что планировщик непредсказуем(unpredictable), когда дело доходит до того, какие потоки(Threads) будут выбраны для запуска в любой момент времени. Приоритеты потоков вместе с событиями events (например, получение данных по сети) делают невозможным определение того, что планировщик решит сделать и когда.
Во-вторых, это означает, что вы никогда не должны писать код, основанный на каком-то предполагаемом поведении, с которым вам посчастливилось столкнуться, но которое не гарантировано будет иметь место каждый раз. Легко позволить себе подумать, потому что я видел, как это происходило 1000 раз, это гарантированное поведение. Вы должны контролировать синхронизацию и оркестровку потоков, если вам нужен детерминизм в вашем приложении.
Физический акт замены потоков(swapping Threads) в ядре называется переключением контекста (context switch). Переключение контекста (context switch) происходит, когда планировщик отключает выполняющийся поток от ядра и заменяет его готовым к выполнению потоком(Runnable Thread). Поток, который был выбран из очереди запуска(the run queue), переходит в состояние выполнения(Executing). Извлеченный поток может вернуться в состояние, пригодное для выполнения (Runnable state) (если у него все еще есть возможность запуска), или в состояние ожидания (Waiting state) (если был заменен из-за запроса(request) типа, связанного с вводом-выводом of an IO-Bound type).
Переключение контекста считается дорогостоящим, поскольку требуется время для переключения потоков между ядром и из него. Величина задержки, возникающей при переключении контекста, зависит от различных факторов, но вполне разумно, чтобы это занимало от ~ 1000 до ~ 1500 наносекунд. Учитывая, что аппаратное обеспечение должно быть способно разумно выполнять (в среднем) 12 инструкций в наносекунду на ядро, переключение контекста может стоить вам от ~ 12 тыс. до ~ 18 тыс. команд с задержкой. По сути, ваша программа теряет способность выполнять большое количество инструкций во время переключения контекста.
Если у вас есть программа, ориентированная на работу с привязкой к вводу-выводу(IO-Bound work), то переключение контекста будет преимуществом. Как только поток переходит в состояние ожидания(Waiting state), другой поток в состоянии, пригодном для выполнения(Runnable state), занимает его место. Это позволяет ядру всегда выполнять работу. Это один из наиболее важных аспектов планирования. Не позволяйте ядру простаивать, если есть работа (потоки в готовом к выполнению состоянии Threads in a Runnable state), которую необходимо выполнить.
Если ваша программа ориентирована на работу с приязкой к ЦП (CPU-Bound work), то переключение контекста станет кошмаром производительности. Поскольку у Thead всегда есть работа, которую нужно выполнить, переключение контекста останавливает выполнение этой работы. Эта ситуация резко контрастирует с тем, что происходит с рабочей нагрузкой, связанной с вводом-выводом (IO-Bound workload)
Чем меньше, тем лучше (Less Is More)
В первые дни, когда процессоры имели только одно ядро, планирование(scheduling) не было чрезмерно сложным. Поскольку у вас был один процессор с одним ядром, в любой момент времени мог выполняться только один поток. Идея заключалась в том, чтобы определить период планирования (scheduler period) и попытаться выполнить все доступные(готовые к выполнению) потоки(Runnable Threads) в течение этого периода времени. Нет проблем: возьмите период планирования и разделите его на количество потоков, которые необходимо выполнить.
В качестве примера, если вы определяете период планирования( scheduler period = 1s) равным 1000 мс (1 секунде) и у вас есть 10 потоков, то каждому потоку дается по 100 мс каждый. Если у вас есть 100 потоков, каждому потоку дается по 10 мс каждый. Однако, что происходит, когда у вас есть 1000 потоков? Выделение каждому потоку временного интервала в 1 мс не работает, потому что процент времени, которое вы тратите на переключение контекста, будет значительным по сравнению с количеством времени, которое вы тратите на работу приложения.
Что вам нужно, так это установить ограничение(limit) на то, насколько маленьким может быть данный временной отрезок. В последнем сценарии, если минимальный временной интервал составлял 10 мс и у вас было 1000 потоков, период планирования необходимо увеличить до 10000 мс (10 секунд). Что, если бы было 10 000 потоков, теперь вы смотрите на период планирования в 100000 мс (100 секунд). При 10 000 потоках с минимальным временным интервалом в 10 мс в этом простом примере для однократного запуска всех потоков требуется 100 секунд, если каждый поток использует свой полный временной интервал.
Имейте в виду, что это очень простой взгляд на мир. Есть еще много вещей, которые необходимо учитывать и обрабатывать планировщику при принятии решений о планировании (scheduling decisions). Вы контролируете количество потоков, используемых в вашем приложении. Когда требуется учитывать больше потоков и выполняется работа, связанная с вводом-выводом(IO-Bound work), возникает больше хаоса и недетерминированного поведения. На планирование и выполнение уходит больше времени.
Вот почему правило игры таково: “Чем меньше, тем лучше(Less is More дословно переводится кем меньше, тем больше, но это не правильно)”. Чем меньше потоков в состоянии готовым к выполненю (Runnable), тем меньше накладных расходов на планирование (scheduling overhead) и больше времени с течением времени получает каждый поток. Чем больше потоков находится в готовом к работе состоянии(Runnable state), тем меньше времени затрачивается на каждый поток с течением времени. Это означает, что со временем также выполняется меньшая часть вашей работы.
Найдите баланс (Find The Balance)
Вам нужно найти баланс между количеством имеющихся у вас ядер и количеством потоков, необходимых для получения максимальной пропускной способности вашего приложения. Когда дело доходит до управления этим балансом, пулы потоков(Thread pools) были отличным решением. Во второй части я покажу вам, что в Go в этом больше нет необходимости. Я думаю, что это одна из приятных вещей, которые Go сделала для упрощения разработки многопоточных приложений.
До написания кода в Go я писал код на C ++ и C # в NT. В этой операционной системе использование пулов потоков IOCP (порты завершения ввода-вывода - IO Completion Ports) было критически важным для написания многопоточного программного обеспечения. Как инженеру, вам нужно было выяснить, сколько пулов потоков вам нужно и максимальное количество потоков для любого данного пула, чтобы максимизировать пропускную способность при том количестве ядер, которое вам было предоставлено.
При написании веб-служб, взаимодействующих с базой данных, магическое количество потоков в 3 потока на ядро, казалось, всегда обеспечивало наилучшую пропускную способность на NT. Другими словами, 3 потока на ядро сводят к минимуму затраты на задержку при переключении контекста при максимальном увеличении времени выполнения на ядрах. При создании пула потоков IOCP я знал, что начинать нужно с минимум 1 потока и максимум с 3 потоков для каждого ядра, которое я определил на хост-машине.
Если бы я использовал 2 потока на ядро, выполнение всей работы заняло бы больше времени, потому что у меня было свободное время, когда я мог бы выполнить работу. Если я использовал 4 потока на ядро, это также занимало больше времени, потому что у меня была большая задержка при переключении контекста. Баланс в 3 потока на ядро, по какой-то причине, всегда казался магическим числом в NT.
Что, если ваша служба выполняет много разных типов работы? Это может привести к разным и непоследовательным задержкам. Возможно, это также создает множество различных событий системного уровня, которые необходимо обработать. Возможно, будет невозможно найти магическое число, которое работает постоянно при всех различных рабочих нагрузках. Когда дело доходит до использования пулов потоков для настройки производительности службы, найти правильную согласованную конфигурацию может быть очень сложно.
Строки кэша (Cache Lines)
Доступ к данным из основной памяти требует такой высокой задержки (от ~ 100 до ~ 300 тактов), что процессоры и ядра имеют локальные кэши для хранения данных рядом с аппаратными потоками, которым они нужны. Доступ к данным из кэшей обходится гораздо дешевле (от ~ 3 до ~ 40 тактов) в зависимости от того, к какому кэшу осуществляется доступ. Сегодня одним из аспектов производительности является то, насколько эффективно вы можете загружать данные в процессор, чтобы уменьшить задержки доступа к данным. При написании многопоточных приложений, изменяющих состояние, необходимо учитывать механику системы кэширования.
Рисунок 2

Обмен данными между процессором и основной памятью осуществляется с помощью строк кэша. Строка кэша - это 64-байтовый фрагмент памяти, которым обмениваются основная память и система кэширования. Каждому ядру предоставляется собственная копия любой необходимой ему строки кэша, что означает, что аппаратное обеспечение использует семантику значений. Вот почему изменения в памяти в многопоточных приложениях могут привести к снижению производительности.
Когда несколько параллельно работающих потоков обращаются к одному и тому же значению данных или даже к значениям данных рядом друг с другом, они будут обращаться к данным в одной строке кэша. Любой поток, запущенный на любом ядре, получит свою собственную копию той же строки кэша.
Рисунок 3
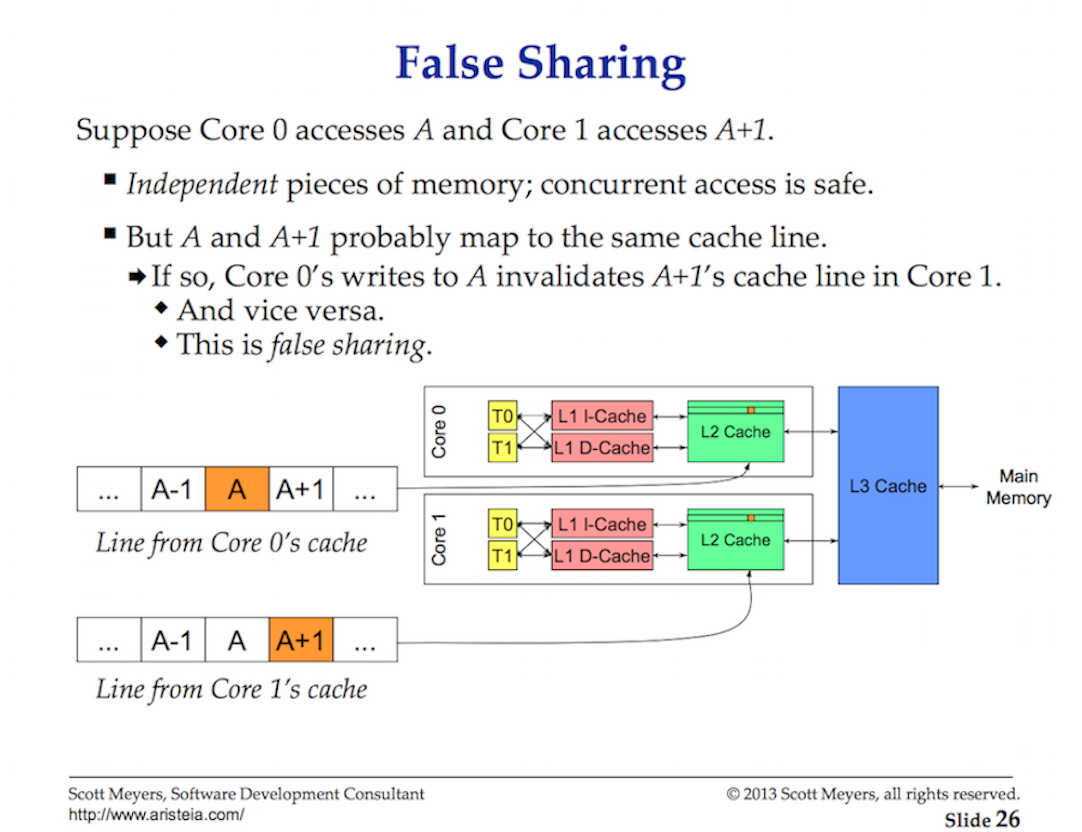
Если один поток в данном ядре вносит изменения в свою копию строки кэша(cache line), то благодаря аппаратному обеспечению все остальные копии той же строки кэша должны быть помечены как “грязные”. Когда Поток пытается получить доступ на чтение или запись к грязной строке кэша, для получения новой копии строки кэша требуется доступ к основной памяти (от ~ 100 до ~ 300 тактов).
Возможно, на 2-ядерном процессоре это не имеет большого значения, но как насчет 32-ядерного процессора, выполняющего 32 параллельных потока, которые получают доступ к данным и изменяют их в одной строке кэша? Как насчет системы с двумя физическими процессорами по 16 ядер в каждом? Ситуация будет хуже из-за дополнительной задержки при передаче данных между процессорами. Приложение будет перегружать память, а производительность будет ужасной, и, скорее всего, вы не будете понимать, почему.
Это называется проблемой согласованности кэша cache-coherency problem или проблемой когерентности кэша, а также приводит к таким проблемам, как ложный обмен данными. При написании многопоточных приложений, которые будут изменять общее состояние, необходимо учитывать системы кэширования.
Сценарий принятия решения о планировании (Scheduling Decision Scenario)
Представьте, что я попросил вас написать планировщик операционной системы на основе предоставленной мной высокоуровневой информации. Подумайте об одном сценарии, который вам нужно рассмотреть. Помните, это одна из многих интересных вещей, которые планировщик должен учитывать при принятии решения о планировании.
Вы запускаете свое приложение, и основной поток создается и выполняется на ядре 1. Когда поток начинает выполнять свои инструкции, извлекаются строки кэша, поскольку требуются данные. Теперь поток решает создать новый поток для некоторой параллельной обработки. Вот в чем вопрос.
Как только поток создан и готов к запуску, следует ли планировщику:
- Контекстное отключение основного потока(main Thread) ядра 1? Это может повысить производительность, поскольку вероятность того, что этому новому потоку понадобятся те же данные, которые уже находятся в кэше, довольно высока. Но основной поток не получает своего полного временного интервала.
- Должен ли (дочерний дополнение от меня) поток ожидать, пока ядро 1 станет доступным, в ожидании завершения временного интервала основного потока? Поток не запущен, но задержка при выборке данных будет устранена после его запуска.
- Должен ли поток ожидать следующего доступного ядра? Это означало бы, что строки кэша для выбранного ядра будут очищаться, извлекаться и дублироваться, вызывая задержку. Однако поток будет запускаться быстрее, и основной поток сможет завершить свой временной отрезок.
Уже развлекаетесь? Это интересные вопросы, которые планировщик операционной системы должен учитывать при принятии решений о планировании. К счастью для всех, их задаю не я. Все, что я могу вам сказать, это то, что, если есть незанятое ядро, оно будет использоваться. Вы хотите, чтобы потоки запускались, когда они могут быть запущены.
Решение от автора сайта оставить одно ядро незанятым, в то время как другие потоки выполняются
Заключение
В этой первой части поста рассказывается о том, что вы должны учитывать в отношении потоков и планировщика операционной системы при написании многопоточных приложений. Это то, что также учитывает планировщик Go. В следующем посте я опишу семантику планировщика Go и то, как они связаны с этой информацией. Затем, наконец, вы увидите все это в действии, запустив пару программ.