Краткое содержание статьи
Протокол группы потребителей: Масштабируемость и отказоустойчивость
- Кафка разделяет хранилище и вычисления между брокерами и потребителями.
- Группы потребителей играют ключевую роль в эффективности и масштабируемости Kafka.
- Группа потребителей определяется с помощью group.id в конфигурации потребителя.
- Единицей параллелизма является разбиение, каждый пользователь может обрабатывать только один раздел.
- Назначение разделов экземплярам группы потребителей происходит динамически и автоматически балансируется при изменении членства.
- Координатор группы помогает равномерно распределять данные и поддерживает баланс при изменении членства в группе.
- Запуск группы потребителей включает поиск координатора группы, присоединение участников и присвоение разделов.
- Стратегии назначения разделов включают распределение диапазона, циклическое распределение и привязку разделов.
- Отслеживание потребления разделов осуществляется с помощью CommitOffsetRequest и OffsetFetchRequest.
- Восстановление баланса в группе потребителей может быть выполнено с помощью StickyAssignor, CooperativeStickyAssignor и статического членства в группе.
Протокол группы потребителей (Consumer Group Protocol)
Kafka отделяет хранение данных от вычислений. Хранение данных осуществляется брокерами, а вычисления в основном осуществляются потребителями или фреймворками, созданными на основе потребителей (Kafka Streams, ksqlDB). Группы потребителей играют ключевую роль в эффективности и масштабируемости потребителей Kafka.
Группа потребителей Kafka (Kafka Consumer Group)
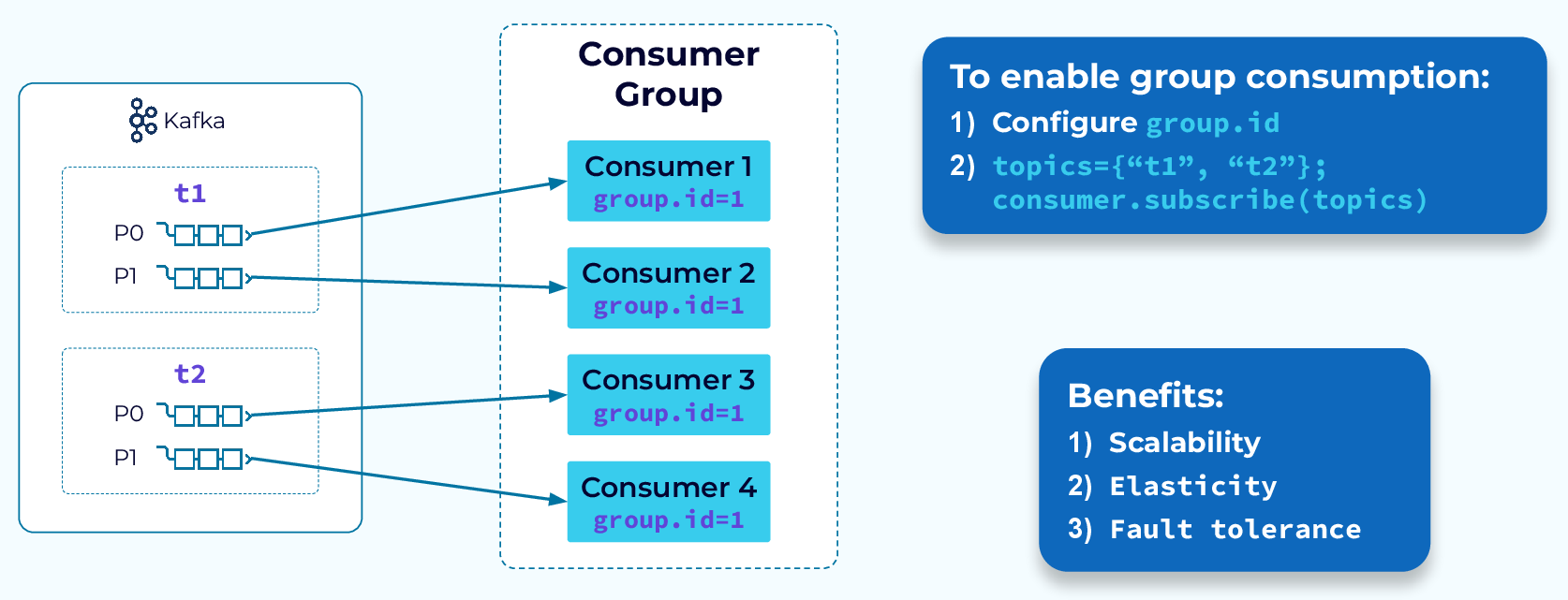
Чтобы определить группу потребителей, нам нужно просто задать group.id в конфигурации потребителя. Как только это будет сделано, каждый новый экземпляр этого потребителя будет добавлен в группу. Затем, когда группа потребителей подписывается на одну или несколько тем, их разделы будут равномерно распределены между экземплярами в группе. Это позволяет выполнять параллельную обработку данных в этих темах.
Единицей параллелизма является раздел. Для заданной группы потребителей потребители могут обрабатывать более одного раздела, но раздел может обрабатываться только одним потребителем. Если наша группа подписана на две темы и каждая из них содержит два раздела, то мы можем эффективно использовать до четырёх потребителей в группе. Мы могли бы добавить пятого, но он будет простаивать, так как разделы нельзя использовать совместно.
Распределение разделов между экземплярами группы потребителей происходит динамически. По мере добавления потребителей в группу, а также при сбое или удалении потребителей из группы по какой-либо другой причине рабочая нагрузка автоматически перераспределяется.
Координатор группы (Group Coordinator)
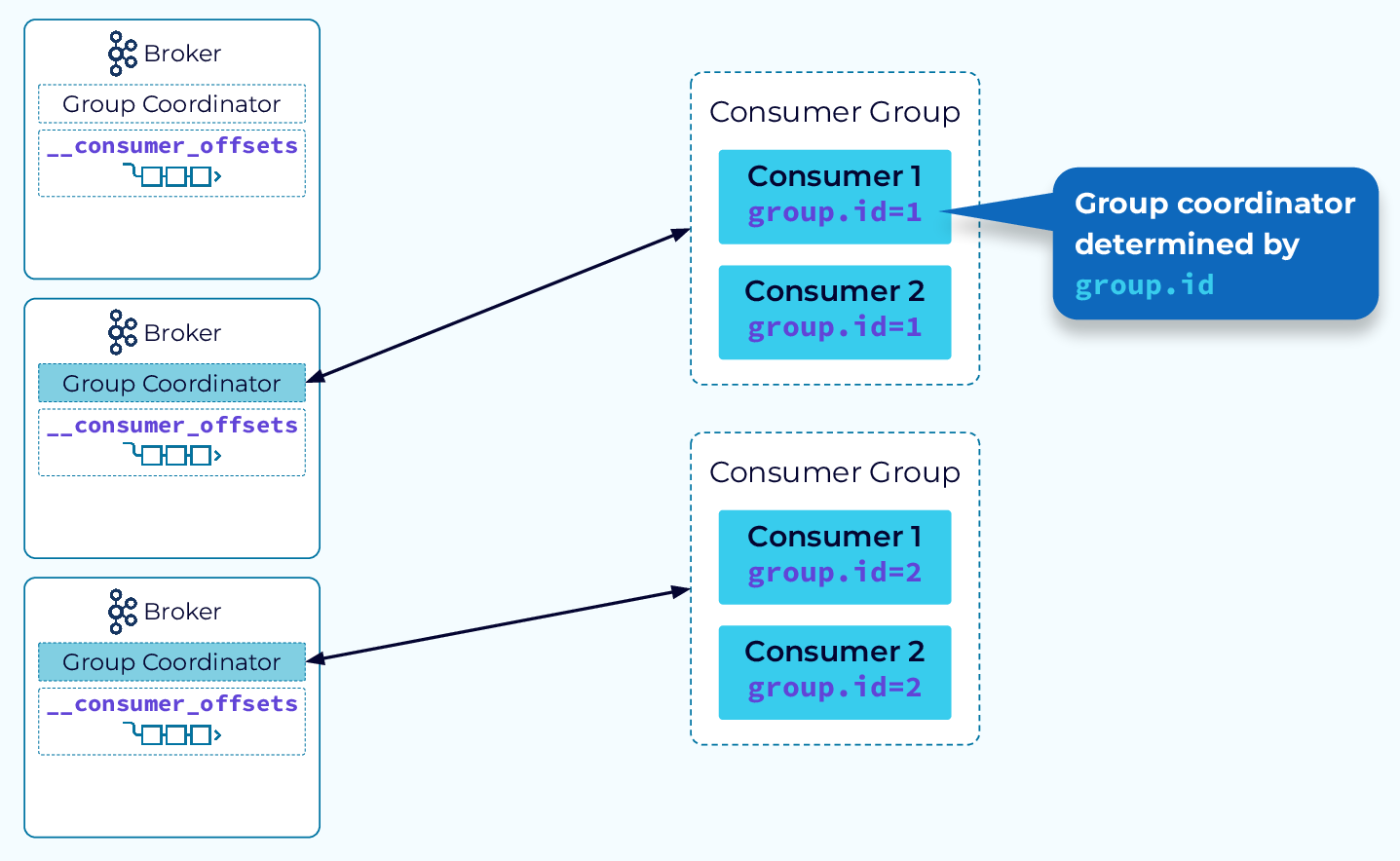
Волшебство, стоящее за группами потребителей, обеспечивается координатором группы. Координатор группы помогает равномерно распределять данные в подписных темах между экземплярами группы потребителей и поддерживает баланс при изменении состава группы. Координатор использует внутреннюю тему Kafka для отслеживания метаданных группы.
В типичном кластере Kafka будет несколько координаторов групп. Это позволяет эффективно управлять несколькими группами потребителей.
Групповой запуск (Group Startup)
Давайте рассмотрим этапы создания новой потребительской группы.
Шаг 1 – Найдите координатора группы
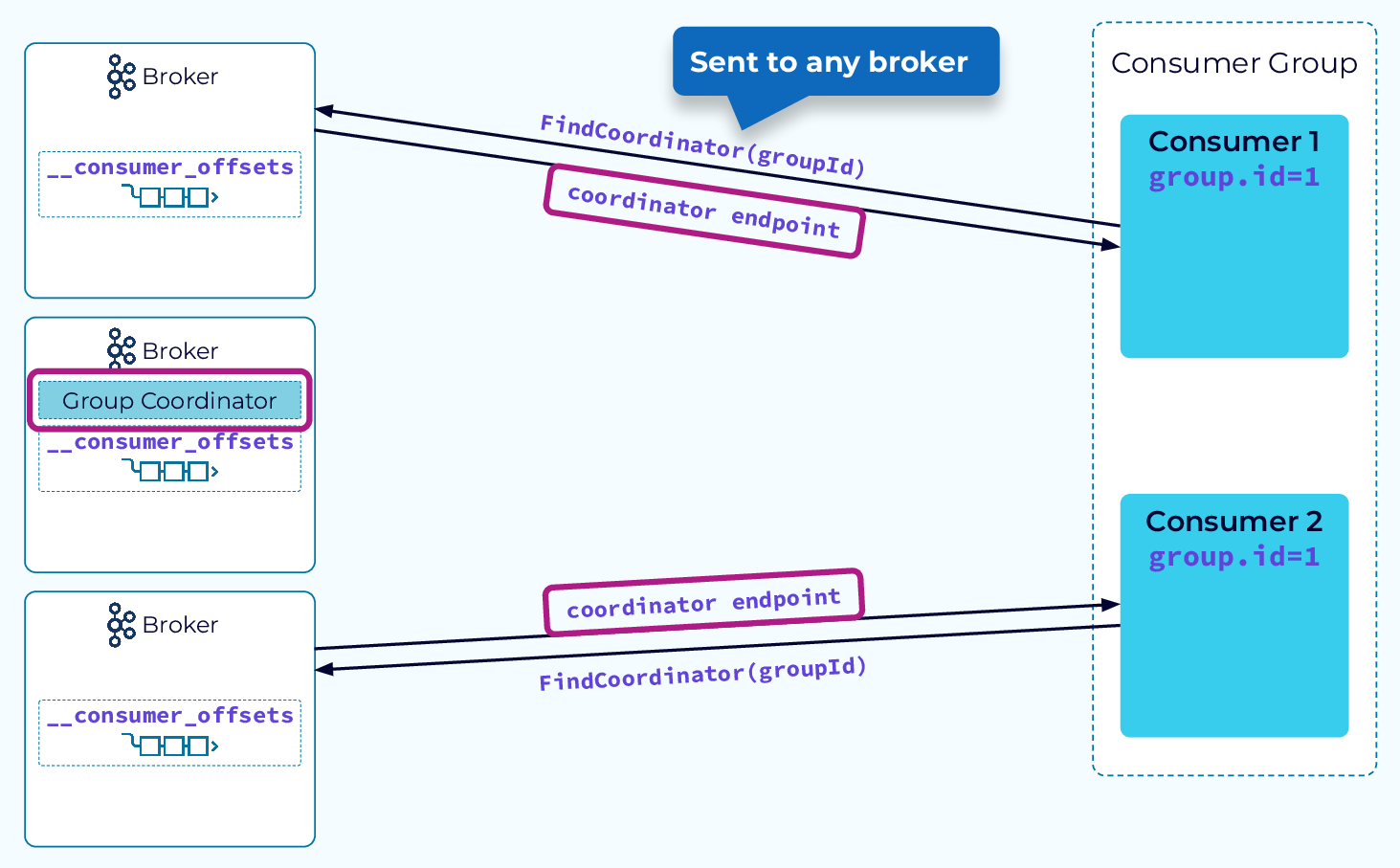
Когда экземпляр потребителя запускается, он отправляет запрос FindCoordinator, включающий group.id, любому брокеру в кластере. Брокер создаст хэш group.id и сравнит его с количеством разделов во внутренней теме __consumer_offsets. Это определяет раздел, в который будут записываться все события метаданных для этой группы. Брокер, на котором находится ведущая реплика для этого раздела, возьмёт на себя роль координатора группы для новой группы потребителей. Брокер, получивший запрос FindCoordinator, ответит конечной точкой координатора группы.
Шаг 2 – Участники присоединяются
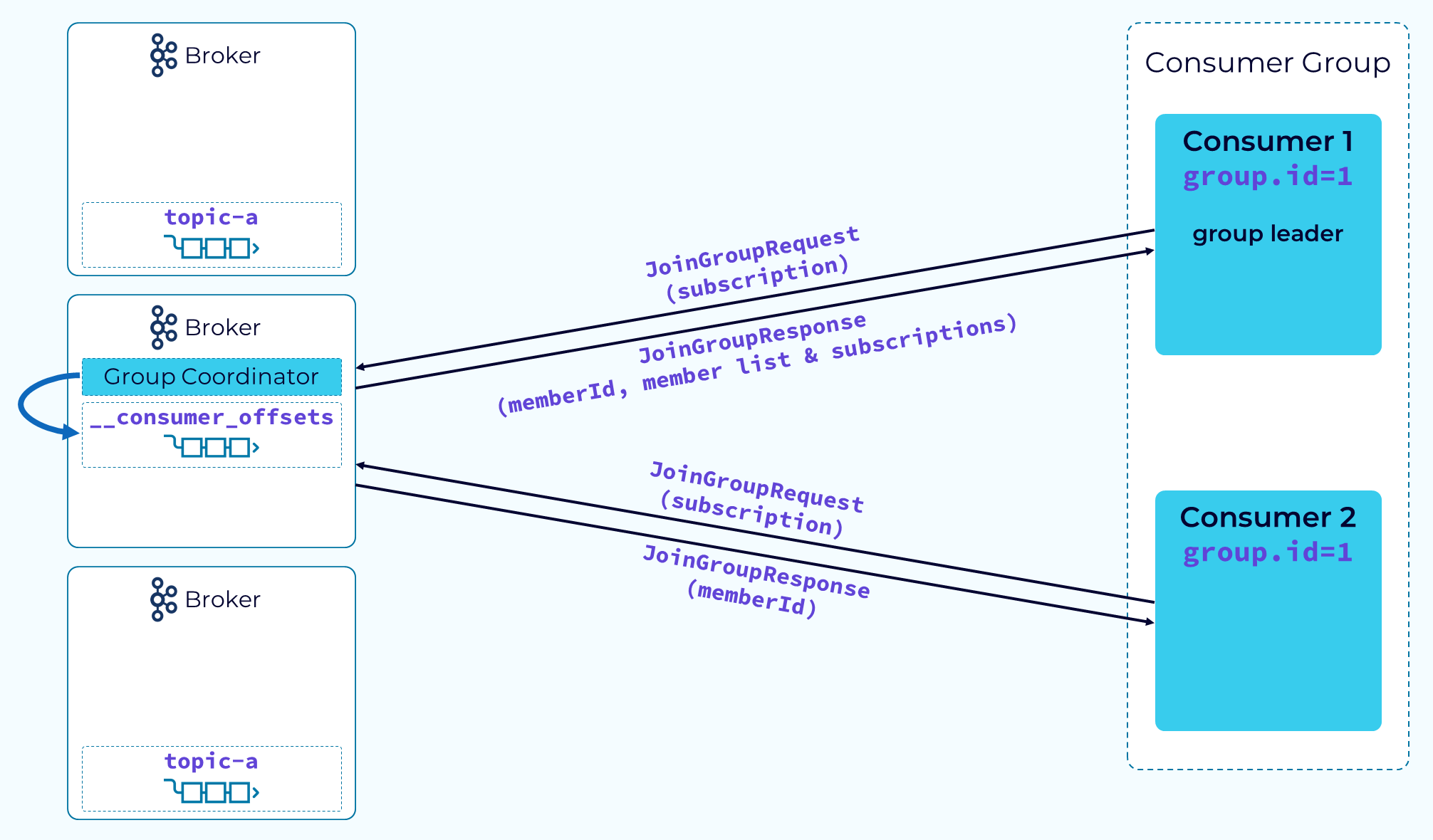
Затем потребители и координатор группы начинают небольшой логистический процесс, который начинается с того, что потребители отправляют запрос JoinGroup и передают информацию о подписке на тему. Координатор выбирает одного потребителя, обычно первого, отправившего запрос JoinGroup, в качестве лидера группы. Координатор возвращает memberId каждому потребителю, но также возвращает список всех участников и информацию о подписке лидеру группы. Это делается для того, чтобы лидер группы мог выполнить фактическое назначение разделов с помощью настраиваемой стратегии назначения разделов.
Шаг 3 – Назначение разделов
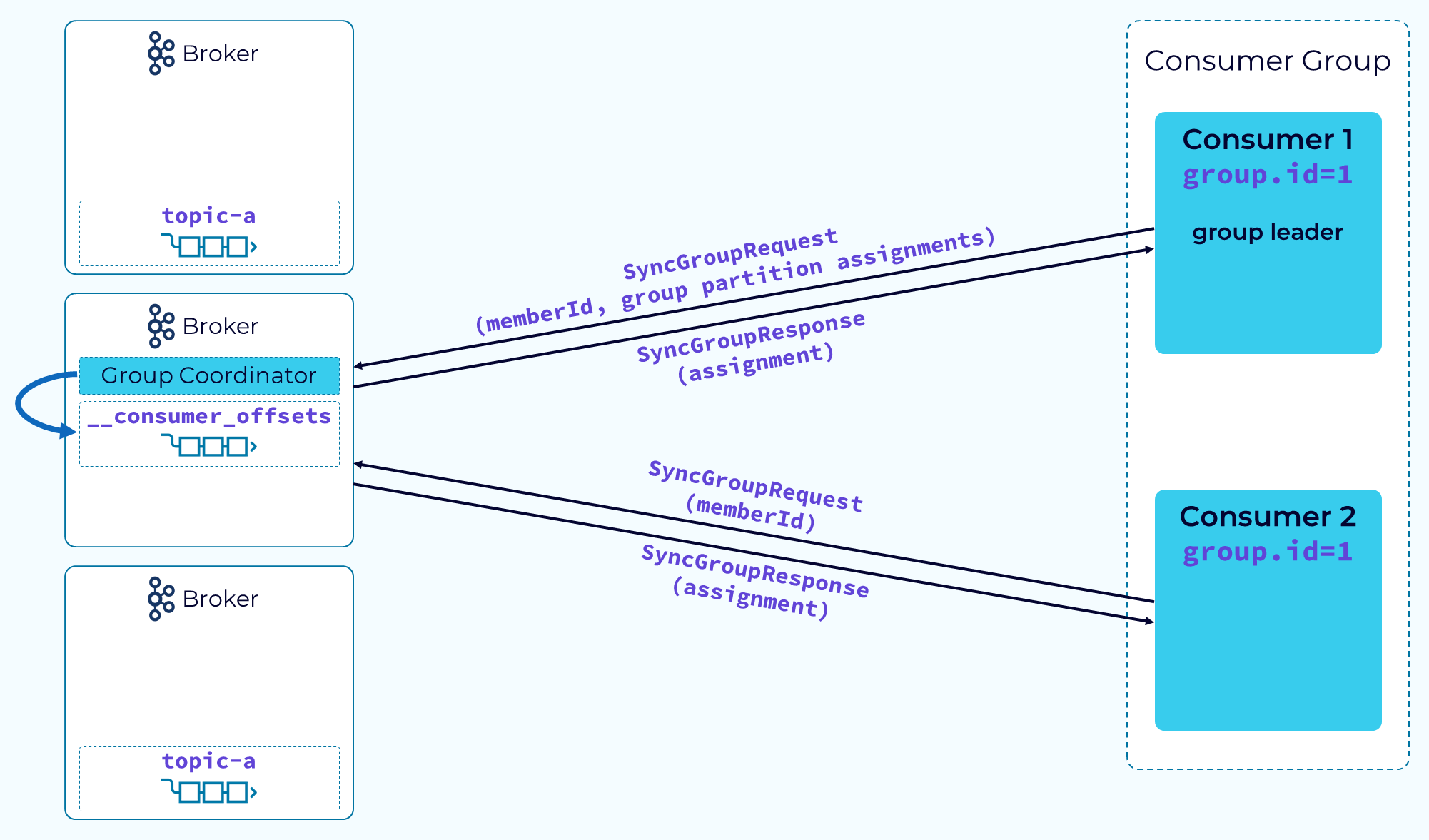
После того как лидер группы получит полный список участников и информацию о подписке, он воспользуется настроенным им разделителем, чтобы назначить разделы подписки участникам группы. После этого лидер отправит SyncGroupRequest координатору, передав свой идентификатор участника и назначения разделов, предоставленные разделителем. Другие участники отправят аналогичный запрос, но передадут только свой идентификатор участника. Координатор воспользуется информацией о назначениях, предоставленной лидером группы, чтобы вернуть фактические назначения каждому участнику. Теперь потребители могут приступить к реальной работе по потреблению и обработке данных.
Стратегия назначения разделов диапазона (Range Partition Assignment Strategy)
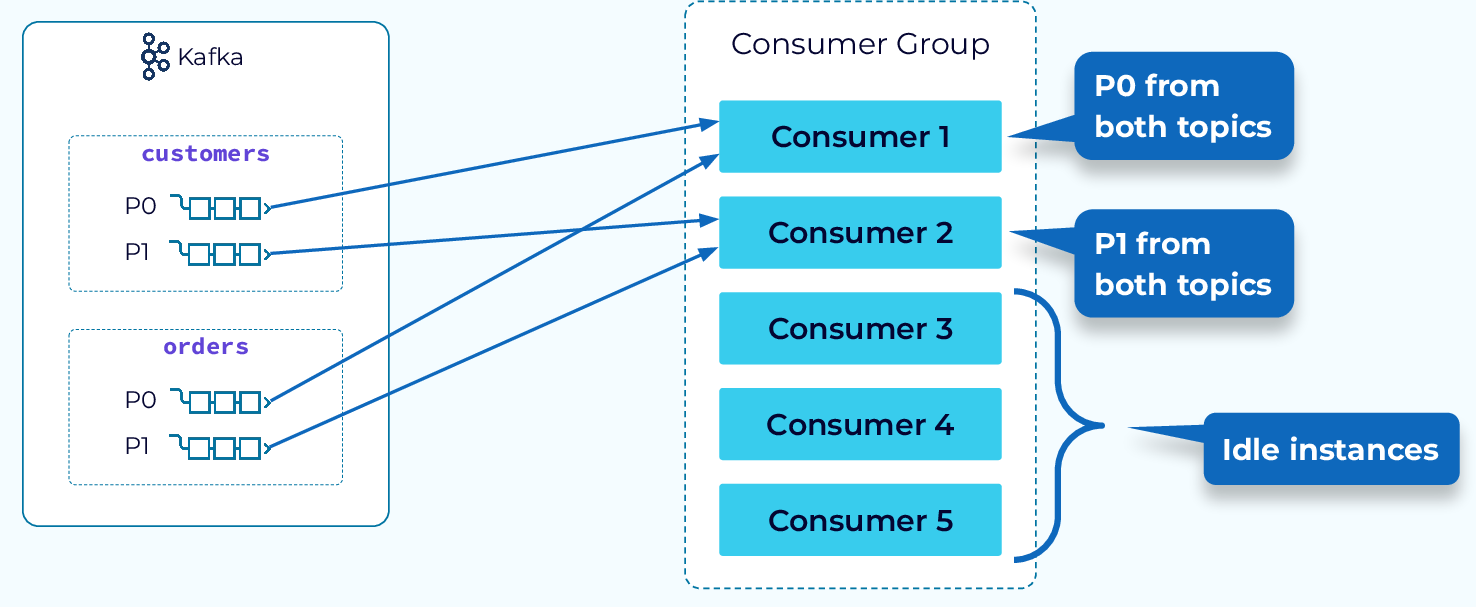
Теперь давайте рассмотрим некоторые доступные стратегии назначения. Начнём со стратегии назначения по диапазону. Эта стратегия просматривает каждую тему в подписке и назначает каждую из секций потребителю, начиная с первого потребителя. Это означает, что первая секция каждой темы будет назначена первому потребителю, вторая секция каждой темы будет назначена второму потребителю и так далее. Если ни одна тема в подписке не содержит столько секций, сколько есть потребителей, то некоторые потребители будут простаивать.
На первый взгляд это может показаться не очень хорошей стратегией, но у неё есть особая цель. При объединении событий из нескольких тем события должны считываться одним и тем же потребителем. Если события в двух разных темах используют один и тот же ключ, они будут находиться в одном и том же разделе соответствующих тем, а с помощью диапазона разделов они будут назначены одному и тому же потребителю.
Стратегии циклического перебора и фиксированного назначения разделов (Round Robin and Sticky Partition Assignment Strategies)
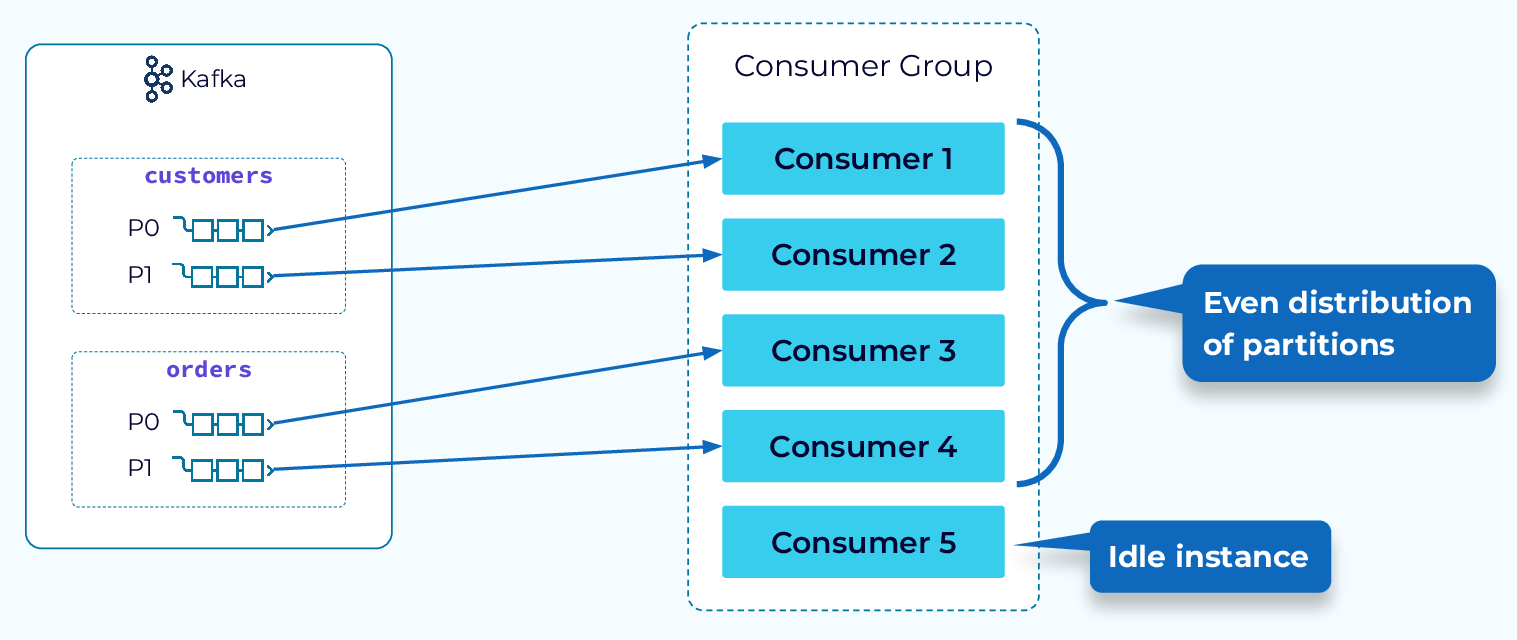
Далее рассмотрим стратегию «Круговой перекрёсток». При использовании этой стратегии все разделы подписки, независимо от темы, будут равномерно распределены между доступными потребителями. Это приводит к меньшему количеству простаивающих экземпляров потребителей и более высокой степени параллелизма.
Вариант стратегии «Круговой перекрёстный опрос», называемый стратегией «Прилипчивый раздел», работает по тому же принципу, но прилагает максимум усилий, чтобы придерживаться предыдущего распределения во время перебалансировки. Это обеспечивает более быструю и эффективную перебалансировку.
Отслеживание потребления разделов (Tracking Partition Consumption)
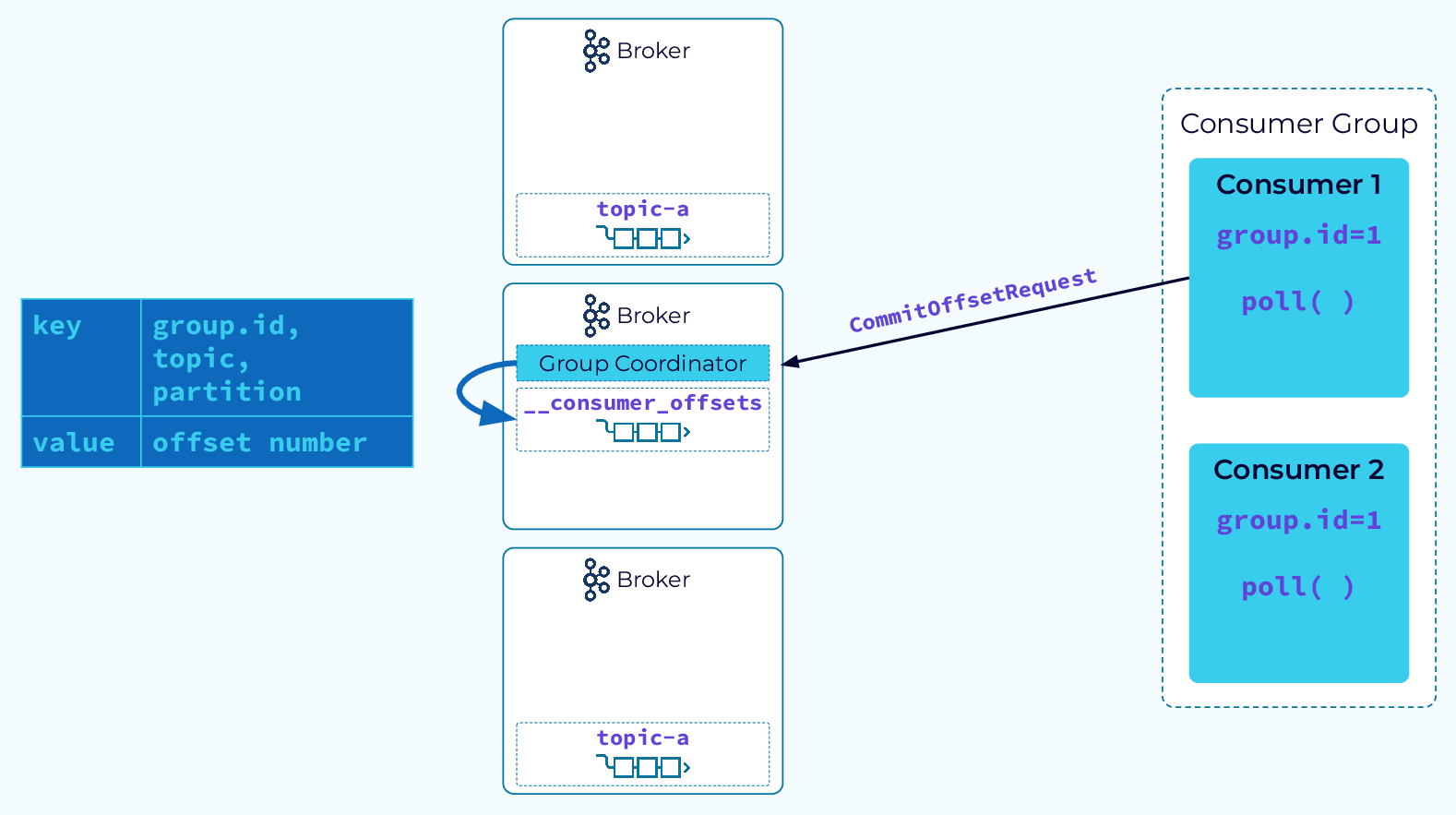
В Kafka отслеживать прогресс потребителя относительно просто. Каждому потребителю всегда назначается один раздел, и события в этом разделе всегда считываются потребителем в порядке смещения. Таким образом, потребителю нужно только отслеживать последнее смещение, которое он прочитал для каждого раздела. Для этого потребитель отправляет CommitOffsetRequest координатору группы. Затем координатор сохраняет эту информацию во внутренней теме __consumer_offsets.
Определение начального смещения для потребления (Determining Starting Offset to Consume)
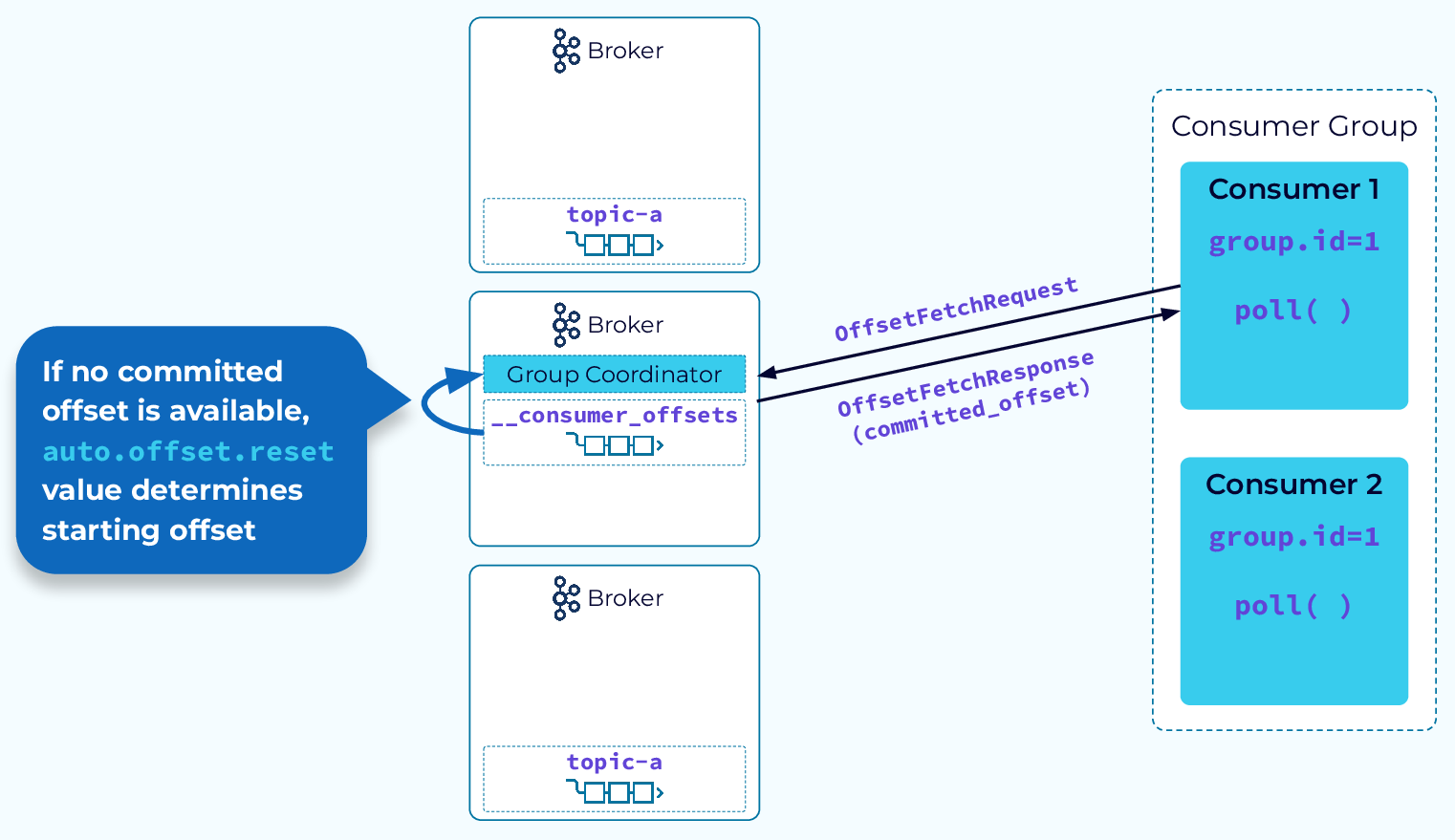
При перезапуске экземпляра группы потребителей он отправит запрос на получение смещения координатору группы, чтобы получить последнее зафиксированное смещение для назначенного ему раздела. Получив смещение, он возобновит потребление с этой точки. Если этот экземпляр потребителя запускается впервые и для этой группы потребителей не сохранено смещение, то конфигурация auto.offset.reset определит, с какого смещения он начнет потребление: с самого раннего или с самого позднего.
Отказоустойчивость координатора группы (Group Coordinator Failover)
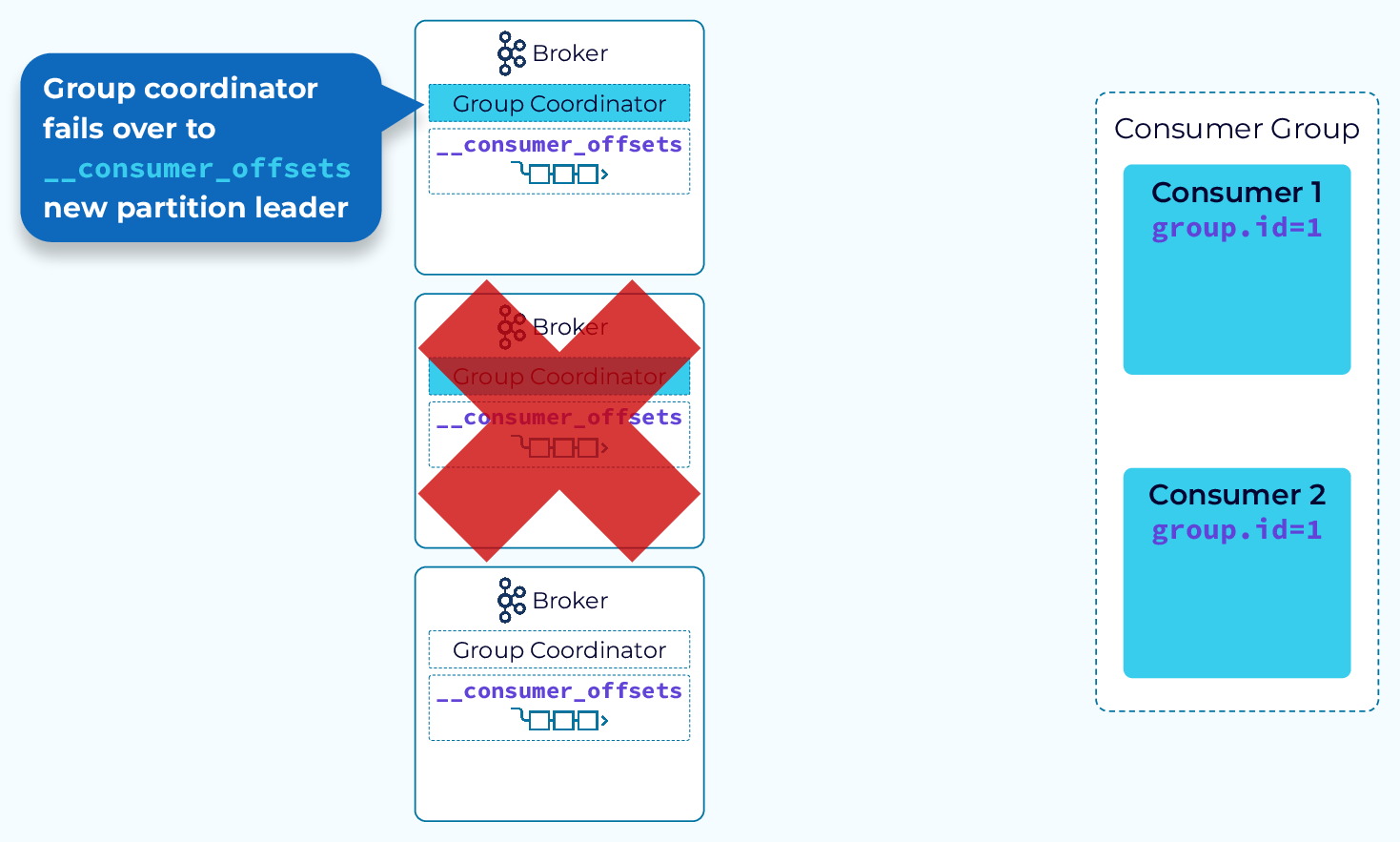
Внутренняя тема __consumer_offsets реплицируется, как и любая другая тема Kafka. Кроме того, помните, что координатор группы — это брокер, на котором размещена ведущая реплика раздела __consumer_offsets, назначенного этой группе. Поэтому, если координатор группы выйдет из строя, новым координатором группы станет брокер, на котором размещена одна из ведомых реплик этого раздела. Потребители будут уведомлены о новом координаторе, когда попытаются выполнить вызов к старому, и затем всё продолжится как обычно.
Триггеры перебалансировки группы потребителей (Consumer Group Rebalance Triggers)
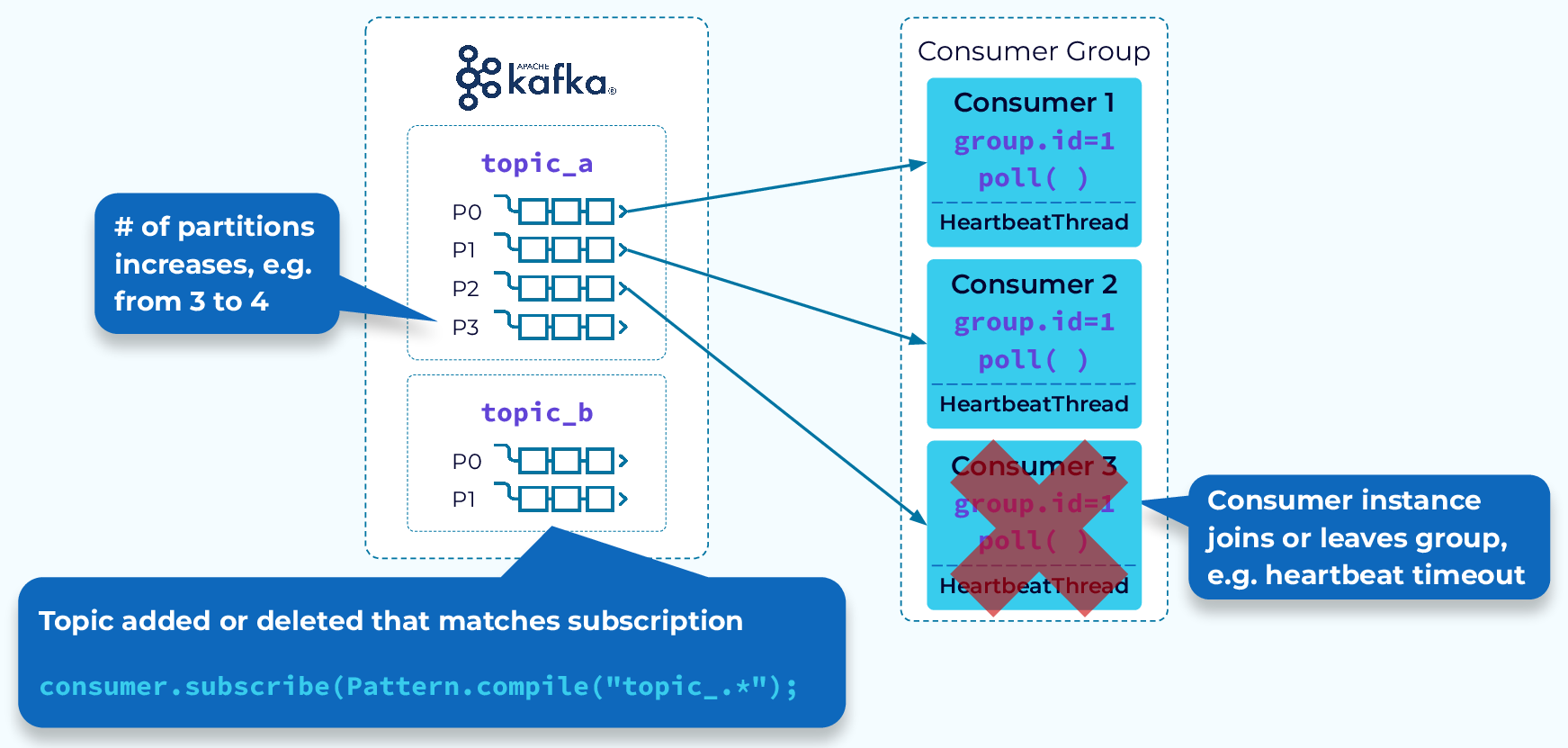
Одной из ключевых особенностей потребительских групп является перераспределение. Мы подробнее обсудим перераспределение, но сначала давайте рассмотрим некоторые события, которые могут привести к перераспределению:
- Экземпляр не отправляет сигнал о состоянии координатору до истечения времени ожидания и удаляется из группы
- В группу добавлен экземпляр
- Разделы добавлены в тему подписки группы
- У группы есть подписка с шаблоном, и создается новая соответствующая тема
- И, конечно же, первоначальный запуск группы
Далее мы рассмотрим, что происходит при перебалансировке.
Уведомление о перебалансировке группы потребителей (Consumer Group Rebalance Notification)
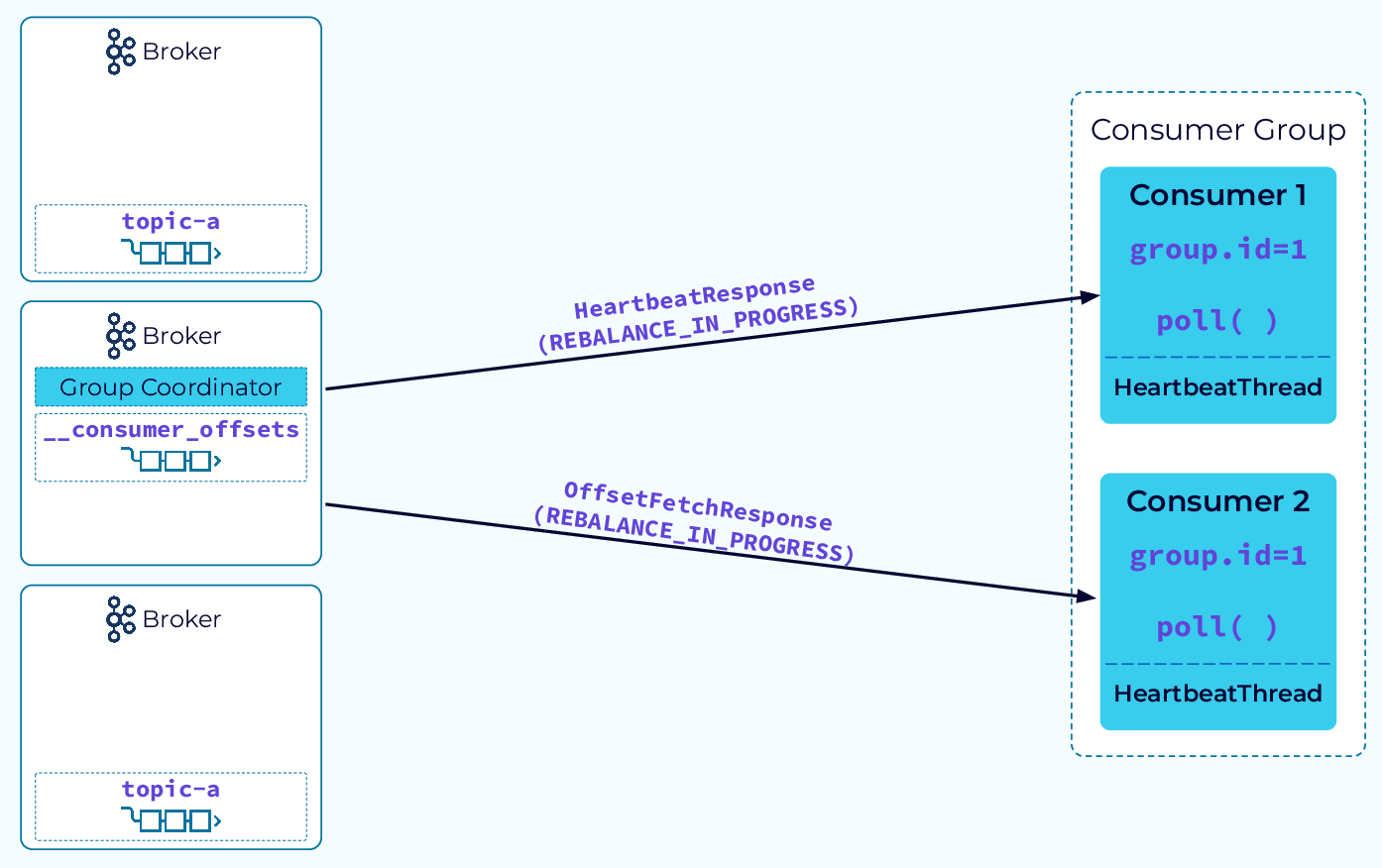
Процесс балансировки начинается с того, что координатор уведомляет экземпляры потребителей о начале балансировки. Он делает это, используя HeartbeatResponse или OffsetFetchResponse. А теперь начинается самое интересное!
Перебалансировка по принципу “Останови мир” (Stop-the-World Rebalance)
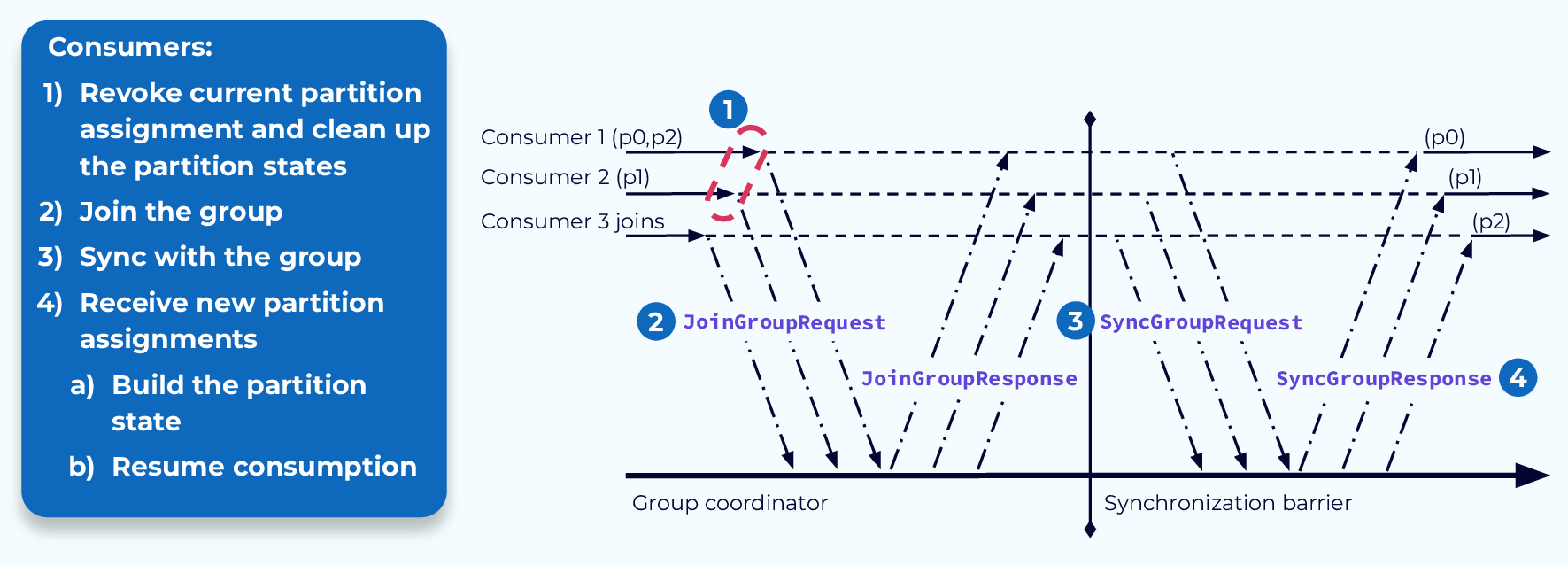
Традиционный процесс балансировки довольно сложен. Как только потребители получат уведомление о балансировке от координатора, они отменят свои текущие назначения разделов. Если они поддерживали какое-либо состояние, связанное с данными в ранее назначенных разделах, им также придется его очистить. Теперь они, по сути, являются новыми потребителями и пройдут те же этапы, что и новый потребитель, присоединяющийся к группе.
Они отправят координатору запрос на присоединение к группе, а затем запрос на синхронизацию группы. Координатор ответит соответствующим образом, и у каждого потребителя появятся новые задачи.
Любое состояние, необходимое потребителю, теперь придётся восстанавливать по данным из вновь назначенных разделов. Этот процесс, хоть и эффективен, имеет некоторые недостатки. Давайте рассмотрим некоторые из них.
Проблема № 1 “Останови мир” - состояние восстановления (Stop-the-World Problem #1 – Rebuilding State)
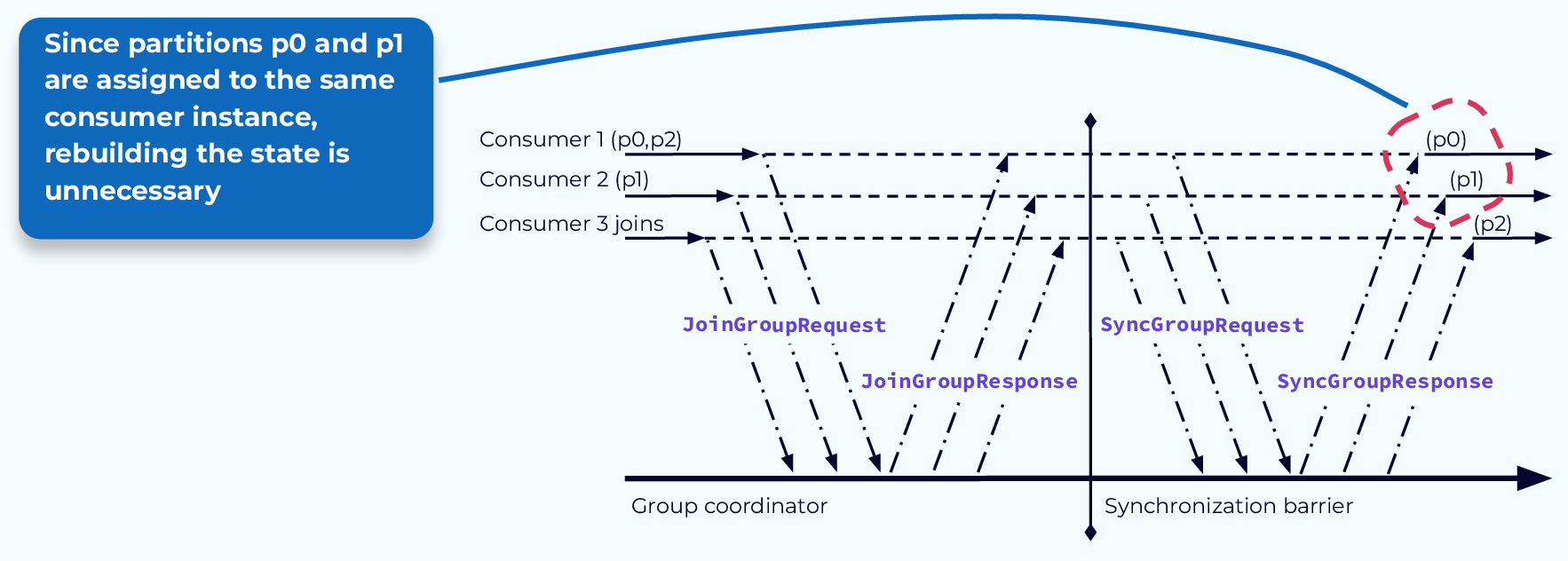
Первая проблема заключается в необходимости восстановления состояния. Если приложение-потребитель поддерживало состояние на основе событий в разделе, к которому оно было подключено, ему может потребоваться прочитать все события в разделе, чтобы восстановить это состояние после завершения балансировки. Как видно из нашего примера, иногда эта работа выполняется даже тогда, когда она не нужна. Если потребитель отменяет подключение к определённому разделу, а затем подключается к тому же разделу во время балансировки, может возникнуть значительная избыточная обработка.
Проблема № 2 “Останови мир” - приостановленная обработка (Stop-the-World Problem #2 – Paused Processing)
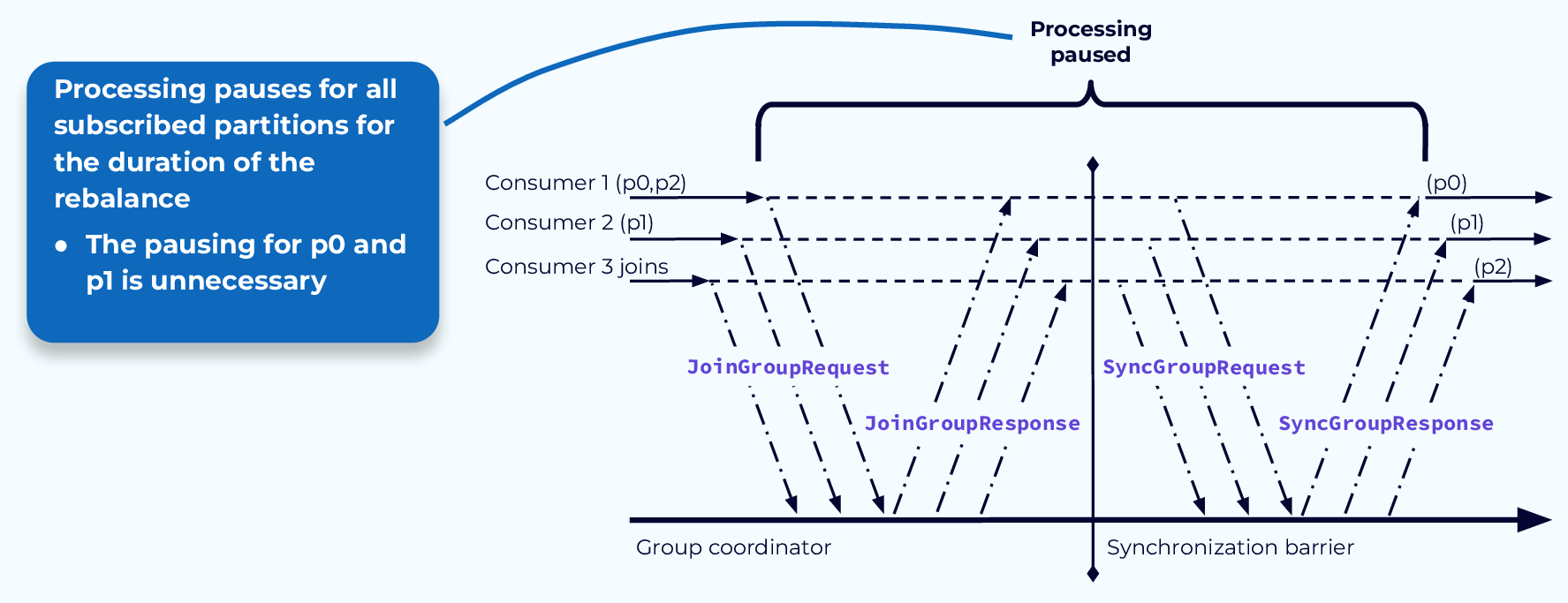
Вторая проблема заключается в том, что нам нужно приостановить все процессы обработки во время перебалансировки, отсюда и название «Останови мир». Поскольку назначения разделов для всех потребителей отменяются в начале процесса, ничего не может произойти, пока процесс не завершится и разделы не будут переназначены. Во многих случаях, как в нашем примере, некоторые потребители сохранят некоторые из тех же разделов и теоретически могли бы продолжать работать с ними во время перебалансировки.
Давайте рассмотрим некоторые улучшения, которые были внесены для решения этих проблем.
Избегайте ненужного восстановления состояния с помощью StickyAssignor (Avoid Needless State Rebuild with StickyAssignor)
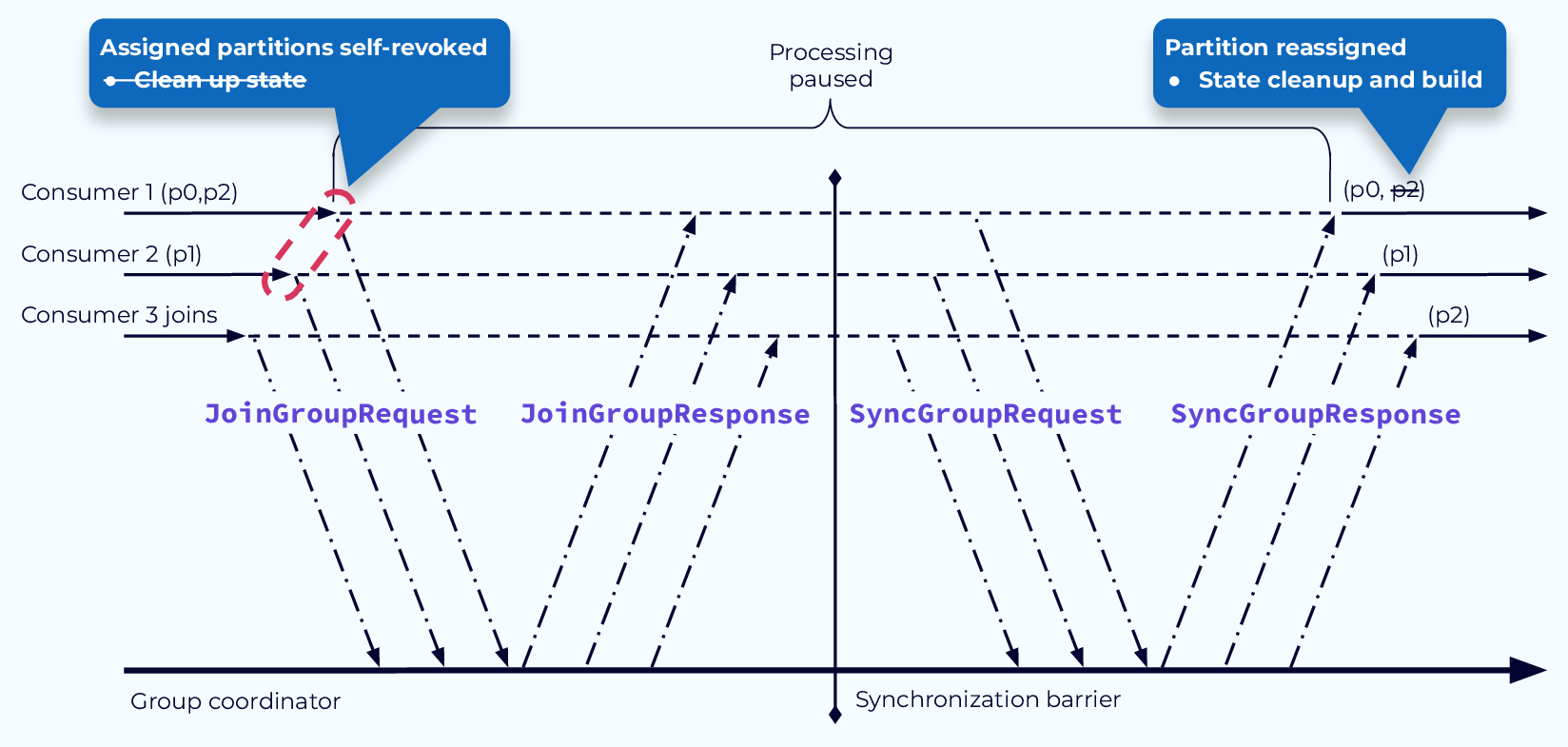
Во-первых, используя новый StickyAssignor, мы можем избежать ненужной повторной настройки состояния. Основное отличие StickyAssignor в том, что очистка состояния переносится на более поздний этап, после завершения переназначения. Таким образом, если потребителю переназначается тот же раздел, он может просто продолжить работу, не очищая и не восстанавливая состояние. В нашем примере состояние нужно будет восстановить только для раздела p2, который назначается новому потребителю.
Избегайте пауз с помощью CooperativeStickyAssignor Шаг 1 (Avoid Pause with CooperativeStickyAssignor Step 1)
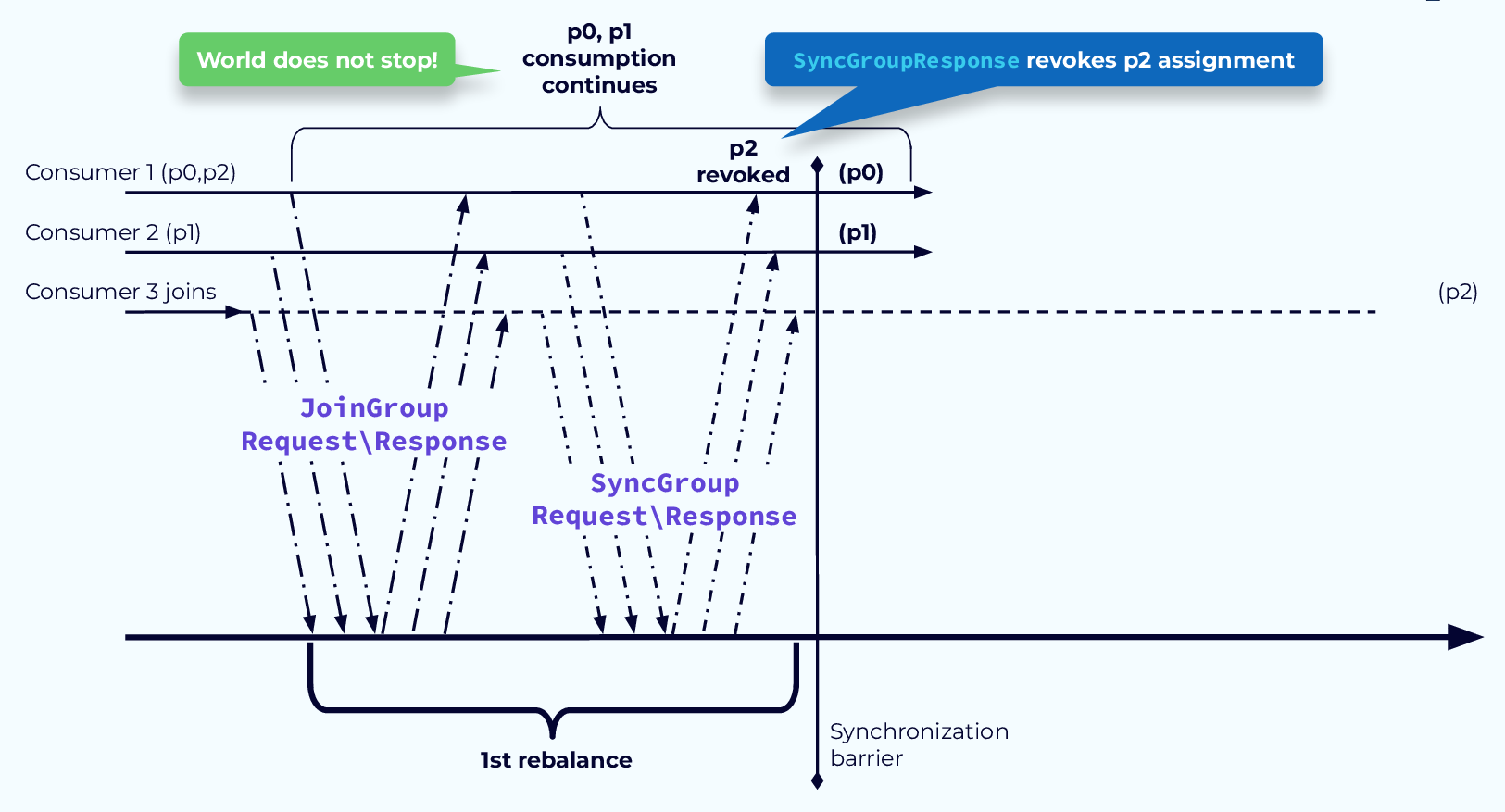
Чтобы решить проблему приостановки обработки, мы внедрили CooperativeStickyAssignor. Этот распределитель работает в два этапа. На первом этапе определяется, какие назначения разделов необходимо отменить. Эти назначения отменяются в конце первого этапа балансировки. Разделы, которые не были отменены, могут продолжать обрабатываться.
Избегайте пауз с помощью CooperativeStickyAssignor Шаг 2 (Avoid Pause with CooperativeStickyAssignor Step 2)
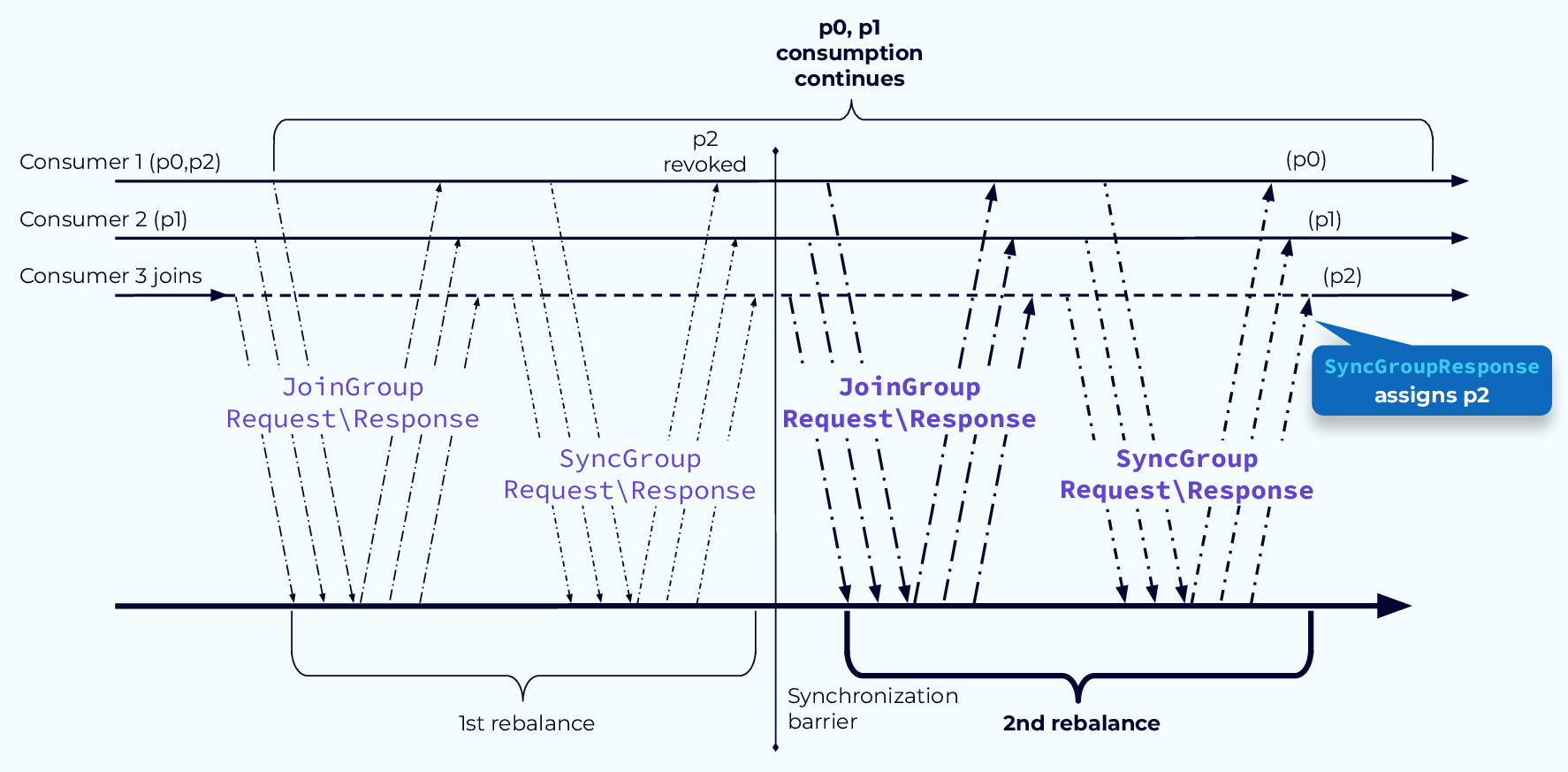
На втором этапе перебалансировки будут назначены отозванные разделы. В нашем примере был отозван только раздел 2, и он был назначен новому потребителю 3. В более сложной системе все потребители могут получить новые разделы, но факт остаётся фактом: разделы, которые не нужно было перемещать, могут продолжать обрабатываться без остановки системы.
Избегайте перебалансировки при статическом членстве в группе (Avoid Rebalance with Static Group Membership)
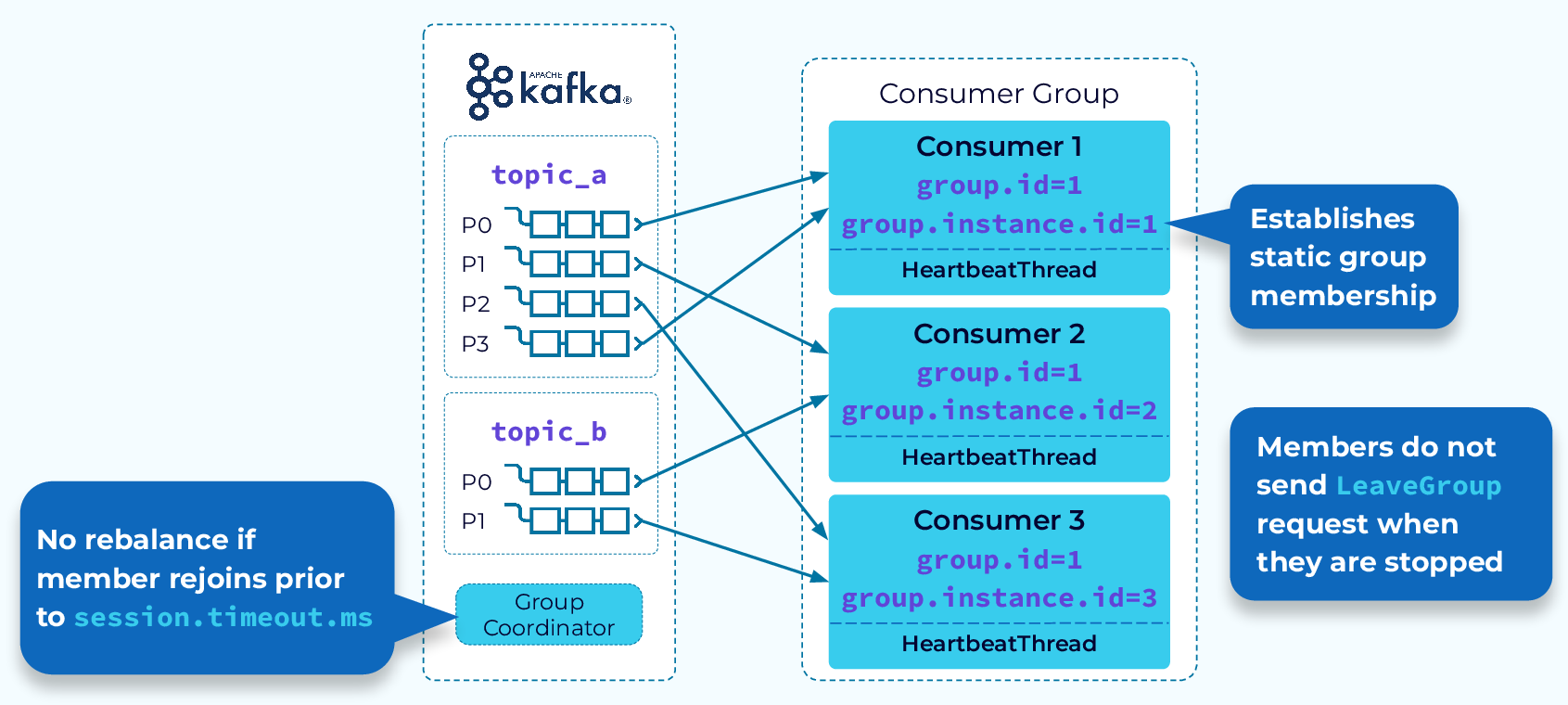
Как говорится, самая быстрая ребалансировка — это та, которая не происходит. В этом и заключается цель статического членства в группе. При статическом членстве в группе каждому экземпляру потребителя назначается group.instance.id. Кроме того, когда экземпляр потребителя корректно завершает работу, он не отправляет координатору запрос LeaveGroup, поэтому ребалансировка не запускается. Когда тот же экземпляр присоединяется к группе, координатор распознает его и позволит ему продолжить работу с существующими назначениями разделов. Опять же, ребалансировка не требуется.
Аналогичным образом, если экземпляр потребителя выйдет из строя, но будет перезапущен до истечения интервала ожидания, он сможет продолжить выполнение существующих задач.